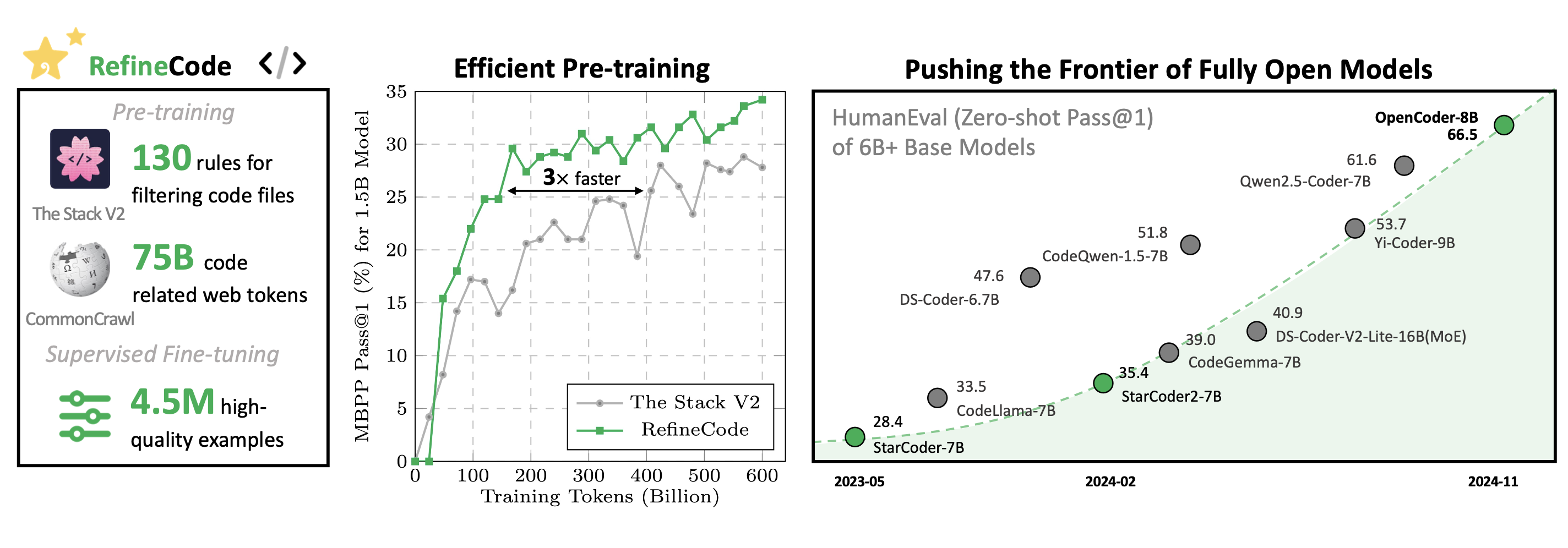
OpenCoder is an open and reproducible code LLM family which includes 1.5B and 8B base and chat models, supporting both English and Chinese languages. Starting from scratch, OpenCoder is trained on 2.5 trillion tokens composed of 90% raw code and 10% code-related web data, reaching the performance of top-tier code LLMs. We provide not only model weights and inference code, but also the reproducible training data, the complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols. Empowering researchers to build and innovate, OpenCoder is your open foundation for advancing code AI.
- OpenCoder: A completely open-source Code LLM, built on the transparent
data process pipeline and reproducible dataset, which achieves top-tier performance on multiple code LLM evaluation benchmarks.
- RefineCode: A high-quality, reproducible code pretraining corpus comprising 960 Billion tokens across 607 programming languages.
- Instructive Ablation Studies: Several meaningful ablation experiments aiming at providing meaningful insight for various design choices and training strategies of code LLMs.
- Released Resources: Final model weights, complete data processing pipeline, efficient evaluation pipeline, reproducible pretraining dataset, large-scale SFT dataset, and intermediate checkpoints.
 OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models